

Por Saroj Kar para Cloud Times.
La firma de investigación IDC, en un informe reciente, muestra que las empresas combinan Hadoop con otras bases de datos para realizar el análisis de datos masivo. Una proporción significativa de los encuestados dijo que Hadoop se utiliza para sustituir las tecnologías de almacenamiento de datos tradicionales. Esto va desde el análisis de los datos en bruto, datos operativos, datos de diferentes equipos, y datos sobre el comportamiento del cliente recogidos por los sistemas de venta de comercio electrónico.
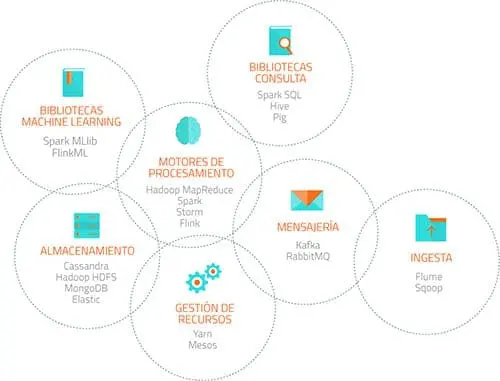
Para gestionar grandes volúmenes de datos, Hadoop implementa el paradigma denominado MapReduce, según el cual las aplicaciones se dividen en pequeñas piezas de software, cada uno de las cuales se pueden ejecutar en un nodo distinto de todos los que componen el sistema.
Los analistas de la firma de investigación Gartner dicen que Hadoop marca un importante desarrollo del proyecto de código abierto. Su objetivo era hacer que la plataforma de datos sea más fácil de usar y más estable. La nueva organización dirigida por YARN, permite la ejecución simultánea de varias aplicaciones en HDFS, el sistema de archivos distribuido, al tiempo que proporciona un mejor seguimiento de los datos a lo largo de su ciclo de vida.
Empresas como Amazon Web Services, Cloudera, Hortonworks, IBM, Intel, MapR Technologies, Pivotal Software, Twitter, Facebook y otros están gestionando su gran volumen de datos y proporcionando información sobre dónde se dirige el mercado utilizando la tecnología de Apache Hadoop. La NASA también confía en Hadoop para manejar grandes volúmenes de datos en proyectos como The Square Kilometer Array, para la visualización del espacio.
Hadoop 2.2 estimula no sólo la forma en que las aplicaciones manejan los datos, sino que también crea nuevas metodologías que antes eran impensables debido a las limitaciones arquitectónicas.


RT @revistacloud: Hadoop 2.0, un gran paso para Big Data http://t.co/S3VNIb8drX
RT @revistacloud: Hadoop 2.0, un gran paso para Big Data http://t.co/S3VNIb8drX
RT @revistacloud: Hadoop 2.0, un gran paso para Big Data http://t.co/S3VNIb8drX
#hadoop 2.0, un gran paso para Big Data http://t.co/oVz1AZV1cd
RT @revistacloud: Hadoop 2.0, un gran paso para Big Data http://t.co/S3VNIb8drX
#Hadoop 2.0, un gran paso para el #BigData. http://t.co/qmpNEMobq4
#Hadoop 2.0, un gran paso para #BigData
La firma de investigación #IDC, en un informe reciente, muestra que las… http://t.co/v18AwtOabV
#Hadoop 2.0, un gran paso para #BigData
La firma de investigación #IDC, en un informe reciente, muestra que las… http://t.co/v18AwtOabV
Hadoop 2.0, un gran paso para Big Data http://t.co/t6MQ0y3i6S vía @revistacloud #hadoop #bigdata
Muchas gracias por la información, no soy ningún experto en Big Data pero ahora mismo lo comparto con mis colegas de trabajo que seguro les encantará la noticia.
Otra pregunta que me ha venido al leer tu artículo:
¿Antiguamente ya se utilizaba la tecnología map reduce en Hadoop?
Un saludo y te sigo de cerca,
Juan.
Hola Juan, si desde el principio Hadoop utilizó la tecnología de MapReduce, como puedes ver aquí: http://hadoop.apache.org/releases.html#4+September%2C+2007%3A+release+0.14.1+available