¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción?
Por Jaime Balañá, Director Técnico de NetApp Iberia.
Las empresas están deseando exprimir el potencial de la inteligencia artificial (IA) y utilizarlo como herramienta para comercializar nuevos servicios y obtener mejor conocimiento a partir de sus datos. Y, sin embargo, al pasar de la fase de prototipo a llevar el Deep Learning a su fase operativa, muchos equipos de análisis experimentan problemas a la hora de gestionar los datos. Es habitual que encuentren dificultades para alcanzar el rendimiento que la solución exige; para transferir y copiar grandes volúmenes de datos o para optimizar el almacenamiento para volúmenes de gran tamaño y en constante crecimiento.
Los flujos de datos necesarios para que una IA funcione con éxito no se limitan a los centros de datos. En un ecosistema en el que empresas de todo tipo adoptan tecnologías en torno a la IA y al Internet de las Cosas (o IoT, según sus siglas en inglés), todas deben enfrentarse al desafío de la gestión de los datos y de su tráfico y movimiento entre el edge (perímetro), el core (centro de datos) y el cloud.
Los retos de cada estadio del ciclo de uso de los datos
NetApp trabaja en colaboración con varias empresas del sector de la automoción que están recabando datos de un número cada vez mayor de vehículos. Su objetivo es utilizar estos datos para desarrollar los algoritmos de IA necesarios para una conducción autónoma. En el proceso, estas empresas están llevando su tecnología computacional al límite.
En un proceso similar, los grandes comercios están creando modelos de inferencia basados en los datos recabados en los puntos de venta de sus cientos de tiendas de todo el mundo. Para la mayoría de comercios, el periodo que va de finales de noviembre a Año Nuevo es el de mayor actividad del año, por lo que resulta fácil imaginarse el gran pico en el volumen de datos que experimentan esas empresas llegadas esas fechas.
Algunos proveedores de servicios suelen transmitir el mensaje de que el reto que representan los datos para IA es puramente una cuestión de rendimiento. Pero esto solo es cierto en una de las fases del flujo de datos de la IA, normalmente la única fase que sus soluciones abordan. Las tecnologías del modelo Data Fabric de NetApp trabajan al unísono para cubrir todo el flujo de los datos, desde su ingesta hasta su archivado, asegurando el éxito de sus operaciones y un gran rendimiento, eficiencia y rentabilidad en cada fase del proyecto.
En el mundo de la IA, el Deep Learning es una de las cargas de trabajo más exigentes, tanto en términos de procesamiento como de I/O de datos. Por ello, todo sistema de canalización de datos que haya sido diseñado con el Deep Learning en mente también podrá lidiar con otras cargas de trabajo relacionadas con la IA y el Big Data.
Los flujos de datos en Deep Learning
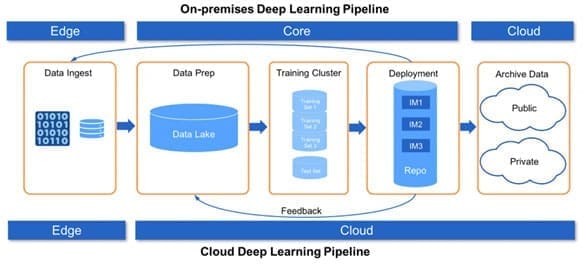
Comencemos por entender los flujos de trabajo necesarios para crear un sistema de Deep Learning como:
- Ingesta de los datos: suele producirse en el edge, por ejemplo, al capturar los datos procedentes de vehículos inteligentes o puntos de venta informatizados. Dependiendo del uso concreto que se le vaya a dar a la IA, puede resultar necesario contar con infraestructura tecnológica en el punto de ingesta de datos o cerca de él. Así, por ejemplo, un comercio puede necesitar un nodo de datos de pequeño tamaño en cada tienda, que consolide todos los datos provenientes de múltiples dispositivos.
- Preparación de los datos: el preprocesamiento de los datos es un paso necesario para que estos presenten un formato homogéneo, antes de utilizarlos para el aprendizaje de la IA. El preprocesamiento de datos se produce en grandes repositorios, a menudo en el cloud en forma de un repositorio S3, o en un almacenamiento de objetos en un centro de datos físico.
- Aprendizaje: esta fase, crítica en todo el proceso, lo más habitual suele ser copiar los datos del repositorio al centro de aprendizaje a intervalos regulares. Los servidores que se utilizan llegados a este punto, utilizan GPU para paralelizar y acelerar el aprendizaje, lo que se traduce en un enorme consumo de datos. En esta fase, el ancho de banda bruto de I/O es clave.
- Implementación: el modelo resultante se pasa a pruebas y, llegado el momento, a producción. Dependiendo del uso que se le vaya a dar al modelo, éste puede ser desplegado de nuevo en el edge. A continuación, se monitorizan los resultados del modelo en situaciones de uso reales, y los análisis resultantes se transmiten en forma de datos nuevos, que vuelven al repositorio, junto con posibles nuevos datos entrantes, para continuar iterando el proceso.
- Archivado: los datos que dejan de utilizarse, procedentes de iteraciones previas, pueden archivarse indefinidamente. Muchos equipos de IA necesitan archivar estos datos “fríos” en almacenamiento a largo plazo, ya sea en clouds públicos o privados.
Muchos clientes han intentado configurar este proceso, ya sea en el cloud o en instalaciones físicas, empleando hardware de consumo y planteamientos de fuerza bruta para la gestión de los datos. Dado el coste prohibitivo de mover todos los datos fuera del cloud una vez han sido enviados a éste, lo más probable en estos casos es que el resto de la canalización se acabe realizando en el cloud. En cualquier caso, inevitablemente se dan cuellos de botella conforme la producción continúa y el volumen de los datos sigue aumentando.
El mayor cuello de botella suele darse en la fase de aprendizaje, en la que se requiere un enorme ancho de banda de I/O y una gran paralelización de la E/S, con el fin de alimentar al centro de aprendizaje de deep learning para el procesamiento de los datos. Tras la fase de aprendizaje, los modelos de inferencia resultantes suelen almacenarse en repositorios de datos tipo DevOps, con las ventajas que conlleva su acceso de ultrabaja latencia.
Si los datos dejan de fluir constantemente a lo largo de la canalización, empezando desde la ingesta misma, la canalización nunca alcanzará plena productividad. Esto se suele traducir en la necesidad de asignar cada vez más horas de personal especializado para gestionar la canalización.
NetApp y la canalización de datos para el Deep Learning
Solo Data Fabric de NetApp ofrece las tecnologías de gestión de datos necesarias para cubrir las necesidades de canalización de datos para el Deep Learning en todas y cada una de sus fases, desde el edge al core y al cloud. Los proveedores de servicios cloud no ofrecen soluciones para el edge y pueden encontrarse con problemas de rendimiento de I/O. Otros proveedores de almacenamiento intentan solventar los problemas de ancho de banda durante la fase de aprendizaje, pero, a pesar de ello, no pueden ofrecer la tan necesaria latencia ultrabaja y carecen de las tecnologías requeridas para cubrir todo el proceso. Aquí es donde Data Fabric de NetApp destaca y ofrece ventajas significativas.
En el edge, NetApp ofrece ONTAP Select, que funciona en hardware de consumo, permite consolidar los datos y ofrece funciones avanzadas para su gestión. Nuestra tecnología MAX Data lanzada recientemente facilita los procesos de ingesta, especialmente para aquellos proyectos en los que las tasas de ingesta sean extremadamente altas.
Para responder a las necesidades en materia de almacenamiento tanto de data lakes como de clústeres de aprendizaje, las soluciones de almacenamiento All Flash FAS de NetApp (o AFF) ofrecen gran rendimiento y capacidad, al tiempo que reducen la necesidad de copias de datos. NetApp está trabajando para ofrecer el máximo beneficio de sus nuevas tecnologías NVMe over Fabrics (NVMe-oF) y MAX Data, expandiendo más si cabe las funcionalidades de sus AFF. NetApp Private Storage (NPS) ofrece muchas de las ventajas que presentan las canalizaciones de Deep Learning en el cloud.
Para el archivado de datos fríos, la tecnología FabricPool de NetApp permite migrar los datos a sistemas de almacenamiento basados en objetos, y gestionarlos mediante políticas.
¿Está preparada su #infraestructura tecnológica para usar flujos de trabajo de IA en fase… https://t.co/d0FlZI12XT
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción?: Por Jaime… https://t.co/h9eainquYI
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción?… https://t.co/RO7vh7VpPO
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción?… https://t.co/8nQBPUCtmI
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción? https://t.co/Rz2miMzclV #Cloud #Tech
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción?… https://t.co/bXtoEBNcYq
¿De qué manera #NetApp canaliza los datos para el Deep Learning con Data Fabric, #ONTAP o #AFF, entre otros? Descúb… https://t.co/tNrRPcLZAl
RT @NetApp_es: ¿De qué manera #NetApp canaliza los datos para el Deep Learning con Data Fabric, #ONTAP o #AFF, entre otros? Descúbrelo de l…
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción? https://t.co/VyqqSmrv2z
RT @NetApp_es: ¿De qué manera #NetApp canaliza los datos para el Deep Learning con Data Fabric, #ONTAP o #AFF, entre otros? Descúbrelo de l…
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción? https://t.co/XF1Gu2me0r
RT @Data_Science_IA: ¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción? @revistacloud…
¿Está preparada su infraestructura tecnológica para usar flujos de trabajo de IA en fase de producción? https://t.co/nH3KfUjseT