
- Por Víctor Manuel Valle, Desarrollador Backend J2EE en Paradigma Digital.
En los últimos años el número de aplicaciones a desarrollar por las empresas ha aumentado considerablemente con la llegada de las arquitecturas basadas en microservicios. Uno de los aspectos más relevantes es la comunicación entre ellos, o la necesidad de tener que integrarse con otros sistemas enviando o recibiendo información. En estos casos, estas comunicaciones deberán ser rápidas, seguras y fiables con una alta disponibilidad.
Una de las soluciones para solventar este tipo de casos han supuesto el uso de tecnologías basadas en colas de mensajes, las cuales permiten la comunicación asíncrona, lo que significa que los puntos de conexión que producen y consumen los mensajes interactúan con la cola, no entre sí.
Además, ayudan a simplificar de forma significativa la escritura de código para aplicaciones desacopladas, mejorando el rendimiento, la fiabilidad y la escalabilidad.
A la hora de utilizar un sistema de colas de mensajes, se ha hecho muy popular el uso de ActiveMQ y RabbitMQ. Sin embargo, a la hora de enfrentarnos a sistemas que requieren la transmisión de datos a tiempo real encontramos Apache Kafka como una de nuestras mejores soluciones.
¿Qué es Apache Kafka?
Apache Kafka es un sistema de transmisión de datos distribuido con capacidad de escalado horizontal y tolerante a fallos. Gracias a su alto rendimiento nos permite transmitir datos en tiempo real utilizando el patrón de mensajería publish/subscribe.
Kafka fue creado por LinkedIn y actualmente es un proyecto open source mantenido por Confluent, empresa que está bajo la administración de Apache. Sus principales funcionalidades son:
- Publicar y suscribirse a flujos de datos (streams), actuando de forma similar a un sistema de colas de mensajes pero con un alto rendimiento obteniendo latencias muy bajas en la transmisión de mensajes. Nos ofrece la posibilidad de dividir el procesamiento de datos en múltiples instancias de consumidores, lo que le permite escalar su procesamiento.
- Permite almacenar streams y se replican para ofrecer una tolerancia a fallos. Kafka permite a los productores esperar el reconocimiento para que una escritura no se considere completa hasta que esté completamente replicada y se garantice que persiste.
- Facilita el procesamiento de streams en tiempo real, pudiendo transformar los datos que se almacenan en Kafka.
Desde Apache recomiendan el uso de Kafka generalmente en dos tipos de aplicaciones:
- En sistemas o aplicaciones que requieren una transmisión de streams entre ellas de manera fiable.
- En sistemas de procesamiento a tiempo real que transforman o reaccionan a los streams.
Estructura
Topics, mensajes y particiones
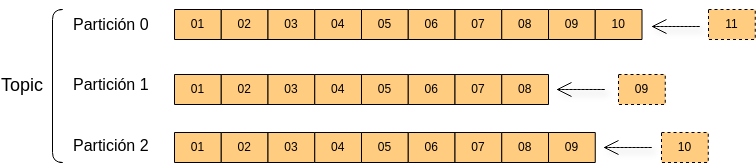
Un topic es un flujo de datos sobre un tema en particular. Podemos crear tantos topics como queramos y estos serán identificados por su nombre. Los topics pueden dividirse en particiones en el momento de su creación.
Cada elemento que se almacena en un topic se denomina mensaje. Los mensajes son inmutables y son añadidos a una partición determinada (específica definida por la clave del mensaje o mediante round-robin en el caso de ser nula) en el orden el que fueron enviados, es decir, se garantiza el orden dentro de una partición pero no entre ellas.
Cada mensaje dentro de una partición tiene un identificador numérico incremental llamado offset. Aunque los mensajes se guarden en los topics por un tiempo limitado (una semana por defecto) y sean eliminados, el offset seguirá incrementando su valor.
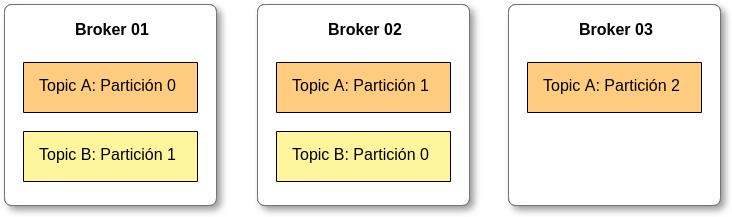
Brokers y Topics
Un clúster de Kafka consiste en uno o más servidores denominados Kafka brokers. Cada broker es identificado por un ID (integer) y contiene ciertas particiones de un topic, no necesariamente todas.
Además, permite replicar y particionar dichos topics balanceando la carga de almacenamiento entre los brokers. Esta característica permite que Kafka sea tolerante a fallos y escalable.
Zookeeper
Se trata de un servicio centralizado imprescindible para el funcionamiento de Kafka, al cual envía notificaciones en caso de cambios como: creación de un nuevo topic, caída de un broker, levantamiento de un broker, borrado de topics, etc.
Su labor principal es gestionar los brokers de Kafka, manteniendo una listado con sus respectivos metadatos y facilitar mecanismos para health checking. Además, ayuda en la selección del broker líder para las distintas particiones de los topics.
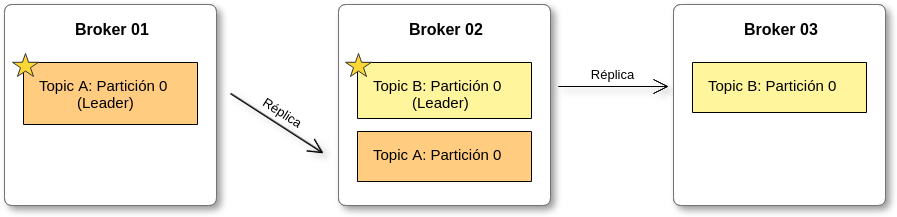
Topic replication
Los topics deberán tener un factor de replicación > 1 (normalmente 2 y 3), de esta forma si un broker se cae, otro broker puede servir los datos.
En cada momento sólo puede haber un broker líder para cada partición de un topic. Sólo el líder puede recibir y servir datos de una partición, mientras tanto los otros brokers sincronizarán sus datos. Si este se cae, se cambia el líder.
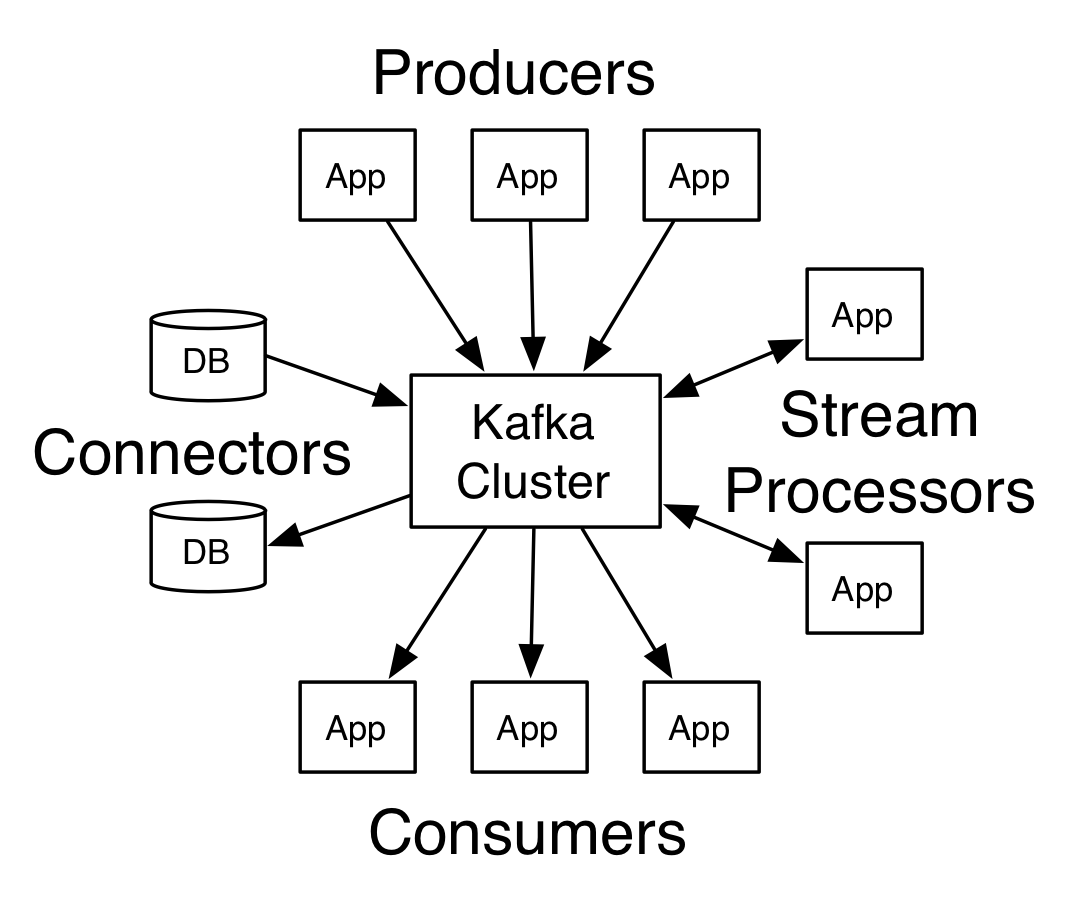
API
Una vez comentada la estructura de Apache Kafka, vamos a ver cómo se interactúa con él mediante cuatro API’s:
Producers
Permite que una aplicación pueda publicar mensajes de un topic de Kafka de forma asíncrona. Los productores automáticamente saben a qué broker y a qué partición deben escribir.
En el caso de que un broker se caiga, el productor sabe cómo recuperarse y seguirá escribiendo en el resto. Los productores envían los mensajes con clave (string, número, etc) o sin ella.
Si la clave es nula se enviarán en round robin entre los brokers. Si no es nula, todos los mensajes con esa clave se enviarán siempre a la misma partición.
Además, para confirmar que los mensajes han sido correctamente escritos en Kafka se podrá configurar la recepción de un ack, ya sea por la recepción del mensaje por parte broker líder o por todos los brokers réplica.
Consumers
Con su uso podemos suscribirnos a un topic de Kafka y consumir sus mensajes para poder tratarlos en nuestra aplicación. Podemos crear un consumidor o un grupo de consumidores.
La diferencia entre ellos es que el grupo de consumidores permite el consumo de mensaje de forma paralela, es decir, si un nodo de ese grupo consume un mensaje el resto no lo hará.
Esto es útil a la hora de tener más de una instancia de un microservicio corriendo en nuestro sistema. Cada consumidor del grupo de consumidores leerá de una partición exclusiva.
Si hay más consumidores que particiones, algunos de los consumidores estarán inactivos, para solucionar esto es recomendable tener el mismo número de particiones que de consumidores dentro de un grupo.
En el caso de que un broker de los que está leyendo se caiga, los consumidores saben cómo recuperarse. Los datos son leídos en orden dentro de cada partición pero no entre ellas. Kafka almacena los offsets de los grupos de consumidores cuando estos leen los datos.
Los offsets son almacenados en un topic de Kafka denominado “_consumer_offsets”. Cuando un consumidor de un grupo lee datos de Kafka, se actualiza el offset. Si un consumidor se cae, cuando vuelva a ser levantado seguirá leyendo datos desde donde se quedó anteriormente.
Stream Processors
Se trata de una librería para crear aplicaciones que nos permite consumir un stream de datos de un topic para poder realizar modificaciones sobre los mensajes y escribir en otro topic actuando como productor, es decir, la entrada y la salida de datos son almacenados en el cluster de Kafka.
Combina la simplicidad del desarrollo de aplicaciones en lenguaje Java o Scala con los beneficios de la integración con el cluster de Kafka. Entre sus características destacan su alta capacidad de procesamiento de mensajes por segundo, su escalabilidad y una alta tolerancia a fallos.
Connectors
Se tratan de componentes listos para usar que nos permiten simplificar la integración entre sistemas externos y el cluster de Kafka. Podemos crear y ejecutar productores o consumidores reutilizables que conectan los topics de Kafka a las aplicaciones o sistemas externos, como por ejemplo una base datos.
Además, algunos permiten realizar modificaciones simples sobre los mensajes que irán a los topics de Kafka. Se configuran mediante ficheros properties o a través de su API REST y entre sus características destacan ser distribuidos y escalables.
Existen muchos conectores para distintos sistemas, en este link podéis encontrar más información.
Conclusiones
En este post hemos realizado una introducción de los aspectos principales de Apache Kafka, así como una explicación de sus principales componentes para una comprensión rápida del producto.
Además, hemos podido comprobar cómo el proceso de integración con nuestros proyectos con Spring es algo sencillo y nos ofrece una gran variedad de opciones a la hora de configurarlo.
Actualmente lo estamos utilizando en nuestro proyecto, siendo una pieza clave en la evolución del mismo, convirtiéndose en uno de los principales mecanismos de comunicación entre nuestros microservicios.















Comunicando microservicios con Apache Kafka https://t.co/NIa4N97i09 #cloudcomputing https://t.co/rJrju5P43B
Comunicando microservicios con Apache Kafka https://t.co/OWD9VaNvJQ https://t.co/5LKuT857vh
Comunicando microservicios con Apache Kafka https://t.co/OObrRWz1DQ https://t.co/po9knqpEq8
RT @prosinet: Comunicando microservicios con Apache Kafka https://t.co/yCYIonZEH4
Comunicando microservicios con Apache Kafka: Por Víctor Manuel Valle, Desarrollador Backend J2EE en Paradigma Digit… https://t.co/UXD12XjERC